Next: conclusion
Up: Marine Data Results
Previous: NMO-Stacking process
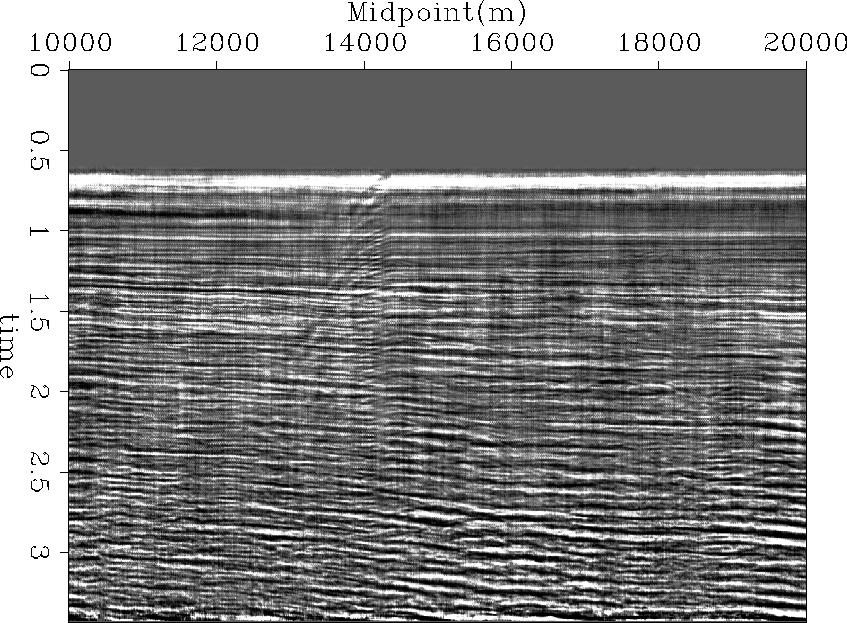
The overall results may seem disappointing: the simple stacking of the input data give
similar results to the stacking of multiple-free gathers using l2, l1 and l1
with l1 regularization. Nonetheless, data with more complex multiples would
certainly lead to different conclusions.
In addition, these data demonstrate that when the gathers are not particularly noisy,
which is the case here, the l1 norm and the l2 norm behave similarly.
The l1 norm with l1 regularization produces expected sparse velocity panels
with very bad convergence properties, meaning that we need to think about new strategies
to improve it. Claerbout (2000, Personal communication) recently suggested that I minimize
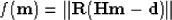
where R is the Prediction Error Filter (PEF) of the residual. The PEF
would help to obtain Independent Identically Distributed (IID) variables in
the residual. Another idea is to minimize
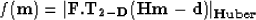
where F.T2-D is the 2-D Fourier Transform. The idea behind this last equation is that
the far offset data, which the l1 norm with l1 regularization does not fit very well, creates
(almost) mono-frequency patterns in the residual that would map in a very localized
area of the Fourier space with high amplitudes (two points for a perfectly
mono-frequency event with one slope). The Huber norm with an appropriate threshold
would treat these focused energies as outliers and get rid of them.
stack_IN
Figure 9 Stacked section of the input data with multiples.




 stack_L2
stack_L2
Figure 10 Stacked section after multiple suppression
using the l2 norm.
comp_stack_L2
Figure 11 Difference between the stacked section
with multiples and the stacked section without multiples using the l2 norm.
stack_L1
Figure 12 Stacked section after multiple suppression
using the l1 norm.
comp_stack_L1
Figure 13 Difference between the stacked section
with multiples and the stacked section without multiples using the l1 norm.
stack_L1L1
Figure 14 Stacked section after multiple suppression
using the l1 norm with l1 regularization.
comp_stack_L1L1
Figure 15 Difference between the stacked section
with multiples and the stacked section without multiples using the l1 norm with l1
regularization.
Next: conclusion
Up: Marine Data Results
Previous: NMO-Stacking process
Stanford Exploration Project
4/27/2000