




Kirchhoff prestack migration is based on the Kirchhoff boundary integral solution to the scalar wave equation. It is a mathematical statement of Huygens' principle that the wavefield at any interior point in a volume can be reconstructed by a surface integration of the boundary values of the wavefield, weighted by the Green's function impulse response to the wave operator. The original Kirchhoff migration theory was discussed by French (1975) and Schneider (1978) with respect to post-stack data, but is easily generalized to prestack wavefield continuation and imaging (see Lumley, 1989, for example).
As an integral summation, the migration sum can be expressed as a trace-sequential operation; each seismic trace can be migrated independently of the other traces. Because of the Kirchhoff trace-sequential property, each processor in a massively parallel supercomputer, such as the Connection Machine, can migrate a seismic trace in parallel with the other processors. This suggests loading as many traces as possible into the available processors, and migrating them simultaneously by parallel computation. We refer the reader to Biondi (1991) for alternate approaches to wave-equation algorithms on massively parallel computers.
We implement our parallel philosophy as follows.
Please refer to Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) for the following discussion.
We define an input
data array DATA(nt,nx*ny), where nt is the number of time
samples in the trace, and nx, ny are the number of traces in the
x- and y-directions respectively. We use the cmf$ layout directive
to declare DATA(:serial,:news), which instructs the CM compiler that
DATA will be a 2-D array of dimensions nt by nx*ny, serial
in the first dimension and parallel in the second dimension. Hence,
a given seismic trace will reside completely within a single processor,
denoted by a column of the DATA matrix.
Note that DATA can be filled
with traces from any arbitrary gather or location, since we will also keep
the respective trace header coordinates in parallel vectors of
the form Xr(nx*ny), laid out as Xr(:news). This frees us
to load shot gathers, 3-D CMP binned data, or arbitrarily located traces,
into DATA until each processor is completely saturated. The better
we make simultaneous use of all processors, the more efficient the
algorithm.
for the following discussion.
We define an input
data array DATA(nt,nx*ny), where nt is the number of time
samples in the trace, and nx, ny are the number of traces in the
x- and y-directions respectively. We use the cmf$ layout directive
to declare DATA(:serial,:news), which instructs the CM compiler that
DATA will be a 2-D array of dimensions nt by nx*ny, serial
in the first dimension and parallel in the second dimension. Hence,
a given seismic trace will reside completely within a single processor,
denoted by a column of the DATA matrix.
Note that DATA can be filled
with traces from any arbitrary gather or location, since we will also keep
the respective trace header coordinates in parallel vectors of
the form Xr(nx*ny), laid out as Xr(:news). This frees us
to load shot gathers, 3-D CMP binned data, or arbitrarily located traces,
into DATA until each processor is completely saturated. The better
we make simultaneous use of all processors, the more efficient the
algorithm.
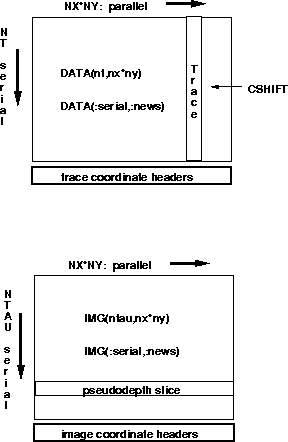 |

We define the output image array as IMG(ntau,nx*ny), where ntau is the number of pseudodepth samples desired in the migrated output. The cmf$ layout instruction declares IMG(:serial,:news), which instructs the CM compiler that IMG will be serial in the first dimension and parallel in the second dimension. We achieve a great efficiency by having the parallel dimensions of both DATA and IMG to be of the same length. This results in a perfect one-to-one overlay of the input and output traces within each processor. This alleviates processor-to-processor communication, which can drastically reduce computational speed, by having all migration calculations done within a single processor, but done in parallel.