




For the operator approach to the fitting goal
![]() we rewrite it as
we rewrite it as
![]() where
where
![\begin{displaymath}
-\bold A_k \bold m_k
\quad \approx \quad
\left[
\begin{arra...
...
m_6
\end{array} \right]
\quad =\quad \bold A \bold J \bold m\end{displaymath}](img16.gif) |
(3) |
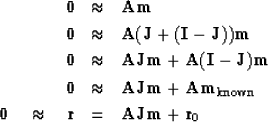 |
(4) | |
| (5) | ||
| (6) | ||
| (7) | ||
| (8) |
| (9) |
We begin the calculation with
the known data values where missing data values are replaced by zeros, namely
![]() .Filter this data,
getting
.Filter this data,
getting ![]() ,and load it into the residual
,and load it into the residual ![]() .With this initialization completed,
we begin an iteration loop.
First we pass the residual through the adjoint
.With this initialization completed,
we begin an iteration loop.
First we pass the residual through the adjoint
| (10) |
| |
(11) |
I could have passed a new operator ![]() into the old solver,
but found it worthwhile to write a new,
more powerful solver having built-in constraints.
To introduce the masking operator
into the old solver,
but found it worthwhile to write a new,
more powerful solver having built-in constraints.
To introduce the masking operator ![]() into the solver
subroutine
into the solver
subroutine ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ,
I introduce an optional input parameter known,
which contains a logical array of the model size.
The values of known are .true. for the known data locations,
and .false. for the unknown data.
Two lines in the simple_solver module
,
I introduce an optional input parameter known,
which contains a logical array of the model size.
The values of known are .true. for the known data locations,
and .false. for the unknown data.
Two lines in the simple_solver module
stat = oper( T, F, g, rr) # dm = A' r
stat = oper( F, F, g, gg) # dr = A dm
become three lines in the standard library module solver_mod.
(Here I changed the comment lines to
correspond to the notation of the missing-data application;
![]() is g and
is g and
![]() is gg.)
is gg.)
stat = oper( T, F, g, rr) # dm = A' r
if ( present( known)) where(known) g = 0. # dm = JJ' dm
stat = oper( F, F, g, gg) # dr = A dm
The new solver initializes its residual exactly as did the original solver, namely,
| (12) |
| (13) |
In Fortran77, I simply multiplied by ![]() .In Fortran90 subroutines can have optional arguments.
The expression
if( present( known)) says, ``if the argument
known, a logical array, is an argument of the call.''
The expression,
where( known) dm = 0 means that each component
of the logical array known is examined;
if the value of that component is .true.
then the corresponding component of
.In Fortran90 subroutines can have optional arguments.
The expression
if( present( known)) says, ``if the argument
known, a logical array, is an argument of the call.''
The expression,
where( known) dm = 0 means that each component
of the logical array known is examined;
if the value of that component is .true.
then the corresponding component of ![]() is set to zero.
In other words, we are not going to change the given, known data values.
is set to zero.
In other words, we are not going to change the given, known data values.
The subroutine to find missing data is mis1().
It assumes that zero values in the input data
correspond to missing data locations.
call tcai1_init( aa, size( mm)); zero = 0.
call solver( tcai1_lop, cgstep, mm, zero, niter,
x0 = mm, known = (mm /= 0.) )
call cgstep_close ()
}
}
module mis_mod {
use tcai1
use cgstep_mod
use solver_mod
contains
# fill in missing data on 1-axis by minimizing power out of a given filter.
subroutine mis1 ( niter, mm, aa) {
integer, intent (in) :: niter # number of iterations
real, dimension (:), pointer :: aa # roughening filter
real, dimension (:), intent (in out) :: mm # in - data with zeroes
# out - interpolated
real, dimension (size(mm) + size(aa)) :: zero # filter output
Here known is declared in solver_mod to be a logical vector.
The call argument known=(xx/=0.) sets the mask vector components
to .true. where components of ![]() are nonzero and sets it
to .false. where the components are zero.
are nonzero and sets it
to .false. where the components are zero.
I sought reference material on conjugate gradients with constraints
and didn't find anything,
leaving me to fear that this chapter was in error
and that I had lost the magic property of convergence
in a finite number of iterations.
I tested the code and it did converge in a finite number of iterations.
The explanation is that these constraints are almost trivial.
We pretended we had extra variables, and computed a ![]() for each of them.
Then we set each
for each of them.
Then we set each ![]() to zero,
making no changes to anything,
like as if we had never calculated the extra
to zero,
making no changes to anything,
like as if we had never calculated the extra ![]() 's.
's.