




Next: The virtual-residual preconditioning algorithm
Up: VIRTUAL-RESIDUAL PRECONDITIONING
Previous: VIRTUAL-RESIDUAL PRECONDITIONING
We begin with the construction of theoretical data
| 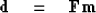 |
(31) |
We assume that there are fewer data points than model points
and that the matrix 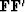 is invertible.
From the theoretical data we estimate a model
is invertible.
From the theoretical data we estimate a model 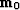 with
with
| 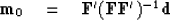 |
(32) |
To verify the validity of the estimate,
insert the estimate (32) into the
data modeling equation (31) and notice
that the estimate predicts the correct data.
Now we will show that of all possible models 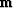 that
predict the correct data, has the least energy.
(I'd like to thank Sergey Fomel for this clear and simple proof
that does not use Lagrange multipliers.)
First split (32) into an intermediate
result
that
predict the correct data, has the least energy.
(I'd like to thank Sergey Fomel for this clear and simple proof
that does not use Lagrange multipliers.)
First split (32) into an intermediate
result 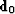 and final result:
and final result:
| 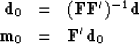 |
(33) |
| (34) |
Consider another model ( not equal to zero)
not equal to zero)
|  |
(35) |
which fits the theoretical data.
Since 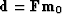 ,we see that is a null space vector.
,we see that is a null space vector.
| 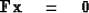 |
(36) |
First we see that is orthogonal to because
|  |
(37) |
Therefore,
| 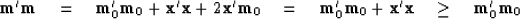 |
(38) |
so adding null space to can only increase its energy.
In summary,
the solution
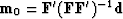 has less energy than any other model that satisfies the data.
has less energy than any other model that satisfies the data.
Not only does the theoretical solution
have minimum energy,
but the result of iterative descent will too,
provided that we begin iterations from 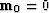 or any with no null-space component.
In (37) we see that the
orthogonality
or any with no null-space component.
In (37) we see that the
orthogonality 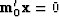 does not arise because has any particular value.
It arises because is of the form
does not arise because has any particular value.
It arises because is of the form 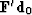 .Gradient methods contribute
.Gradient methods contribute 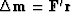 which is of the required form.
which is of the required form.
Next: The virtual-residual preconditioning algorithm
Up: VIRTUAL-RESIDUAL PRECONDITIONING
Previous: VIRTUAL-RESIDUAL PRECONDITIONING
Stanford Exploration Project
2/27/1998