




Such an implementation was not possible for this test. In order to implement the parallel scheme above, each processor must be able to seek and read the traveltime table while no other thread is operating on the file. OpenMP, accounts for such difficulty with the CRITICAL construct. Unfortunately, the CRITICAL construct is not handled correctly by the Portland Group's pgf90 compiler. To overcome this limitation a section of the traveltimes were read in and then the output CMP's within this region were parallelized over.
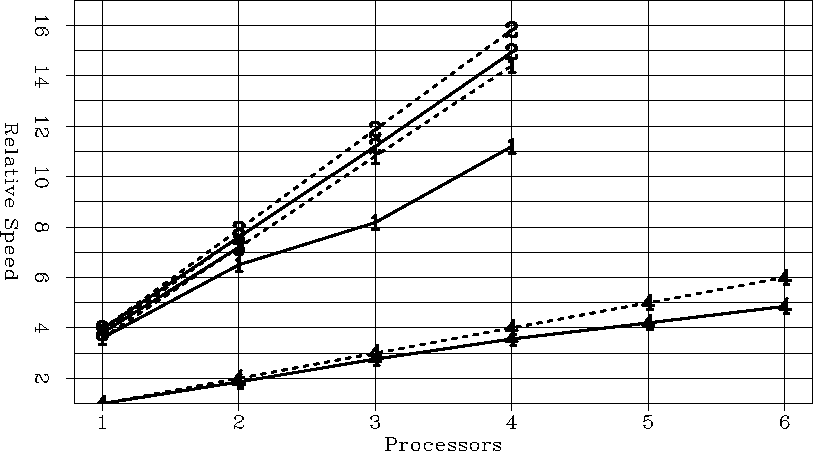
For each of the four computers, we tested the speed both within the parallel region (Figure 7), and of the entire program (Figure 8). Within the parallel region all four machines scaled fairly well. The notable exception being the Origin 200 when going across the Cray Link cable (from two to three processors). For overall speed within the parallel region the Xeon four-processor machine performed the best.
 |

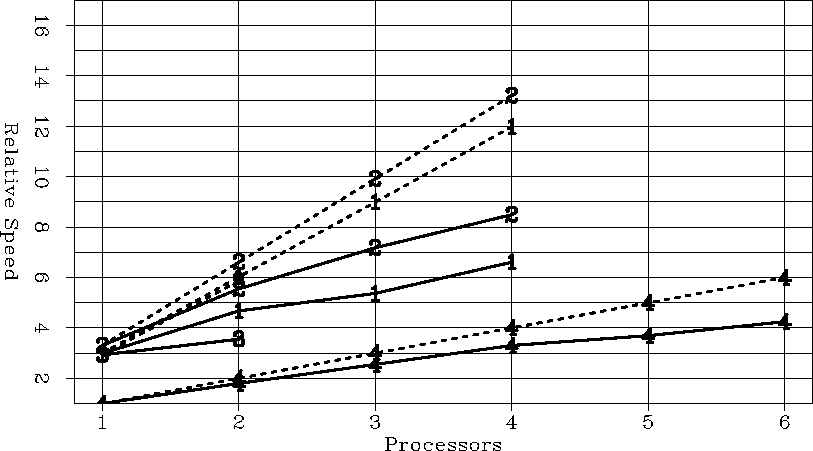 |
For the entire code the results were more interesting. Because Kirchoff migration is so I/O intensive, the performances of the machine's I/O became important. Where the advantage of the Xeon versus the Power Challenge was nearly 4:1 on four processors within the parallel region it was only 2.5:1 when I/O was taken into account. The VA Start X performed particularly poorly when accounting for I/O. Its speed advantage compared to the Power Challenge dropped from 3.9 to 2.1 when accounting for I/O. The VA's I/O problem seems to be more hardware rather than OS related. The Xeon was running the same OS, and saw its speed advantage drop only from 4.1 to 2.7.