




Next: norm
Up: Attenuation of the noise
Previous: Attenuation of the noise
A generally available preconditioning method is to change variables so
that the regularization operator becomes an identity matrix Claerbout and Fomel (2002). The
gradient 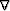 in equation (
in equation (![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ) has no inverse, but its
spectrum
) has no inverse, but its
spectrum 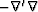 , which appears in equation (),
can be factored (
, which appears in equation (),
can be factored (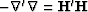 ) into triangular parts
) into triangular parts
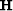 and
and 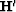 where is known as the Helix
derivative and ()' denotes the adjoint.
This is invertible by deconvolution Claerbout (1998).
The fitting goals in equation () can be then rewritten
where is known as the Helix
derivative and ()' denotes the adjoint.
This is invertible by deconvolution Claerbout (1998).
The fitting goals in equation () can be then rewritten
| 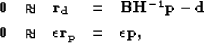 |
(37) |
with 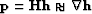 and
and 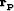 is the
residual for the new variable
is the
residual for the new variable 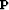 . I then minimize the misfit function
. I then minimize the misfit function
| 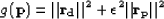 |
(38) |
and finally compute  to estimate the interpolated map
of the lake. Experience shows that iterative solution for converges much
more rapidly than iterative solution for
to estimate the interpolated map
of the lake. Experience shows that iterative solution for converges much
more rapidly than iterative solution for 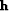 thus showing that
is a good choice for preconditioning.
There is no simple way of knowing beforehand what is the
best value of
thus showing that
is a good choice for preconditioning.
There is no simple way of knowing beforehand what is the
best value of  . Practitioners like to see solutions for
various values of which can be computationally expensive.
Practical exploratory data analysis is more
pragmatic: without a simple clear theoretical basis, analysts
generally begin from
. Practitioners like to see solutions for
various values of which can be computationally expensive.
Practical exploratory data analysis is more
pragmatic: without a simple clear theoretical basis, analysts
generally begin from 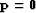 and then abandon the fitting goal
and then abandon the fitting goal
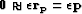 Crawley (2000); Rickett et al. (2001); Trad et al. (2003). Implicitly,
they take
Crawley (2000); Rickett et al. (2001); Trad et al. (2003). Implicitly,
they take 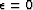 . Then they examine the solution as a function
of iteration, imagining that the solution at larger iterations
corresponds to smaller , and that the solution at smaller iterations
corresponds to larger . In all my computations, I follow this
approach and omit the regularization in the estimation of the depth maps.
. Then they examine the solution as a function
of iteration, imagining that the solution at larger iterations
corresponds to smaller , and that the solution at smaller iterations
corresponds to larger . In all my computations, I follow this
approach and omit the regularization in the estimation of the depth maps.
Next: norm
Up: Attenuation of the noise
Previous: Attenuation of the noise
Stanford Exploration Project
5/5/2005