




Next: NONSTATIONARITY
Up: HOW TO DIVIDE NOISY
Previous: Example of deconvolution with
Pitfalls arise from the popular theoretical analysis explaining  .Since this theory is easily misused,
I'd like to show you the trap.
First, the model Y=FX is supplemented
by an explicit additive noise
.Since this theory is easily misused,
I'd like to show you the trap.
First, the model Y=FX is supplemented
by an explicit additive noise 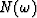 becoming
becoming
| 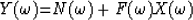 |
(7) |
Because we have many frequencies
we can hope to learn more by averaging over frequency.
Of particular interest is the variance
(described more fully in chapter 11)
| 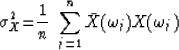 |
(8) |
and likewise 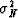 .
.
The general linear estimation method is to minimize something
that looks like a sum of relative errors.
| 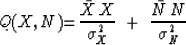 |
(9) |
Notice the variances put both terms of the sum to the same physical units.
Requesting the noise N to be as small as possible seems like a good idea
and asking X to be small too seems to work against any bad effect
of zero division in X=Y/F.
By introducing
(7) into
(9) we can eliminate either N or X.
Eliminating N we have
| 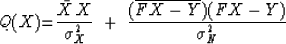 |
(10) |
Minimizing Q(X) by setting its derivative by 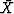 to zero gives
to zero gives
| 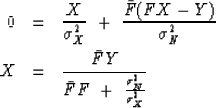 |
(11) |
| (12) |
This completes the ``logical explanation'' of equation (1).
Equation (12) expresses the answer,
but it does so in terms of the unknowns
and
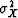 .Given an initial estimate
of
.Given an initial estimate
of 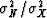 equation (12) gives us X and
(7) gives N,
so we can then compute
and
.Presumably these computed values are better than our initial guesses.
In statistics,
the variances in (12)
are called priors,
and it makes sense to check them,
and even more sense to correct them.
And from the corrected values we should be able to iterate,
further improving the corrections.
Equation (12) applies for each of the many frequencies,
and there is only a single unknown,
the ratio so it seems like there is plenty of information
and the bootstrapping procedure might work.
A pessimist might call this bootstrapping
``self fulfilling prophecy.''
What do you think?
equation (12) gives us X and
(7) gives N,
so we can then compute
and
.Presumably these computed values are better than our initial guesses.
In statistics,
the variances in (12)
are called priors,
and it makes sense to check them,
and even more sense to correct them.
And from the corrected values we should be able to iterate,
further improving the corrections.
Equation (12) applies for each of the many frequencies,
and there is only a single unknown,
the ratio so it seems like there is plenty of information
and the bootstrapping procedure might work.
A pessimist might call this bootstrapping
``self fulfilling prophecy.''
What do you think?
Truth is stranger than fiction.
I tried it.
With my first starting value for
the ratio the iteration led to the ratio being infinite.
Another starting value led to the ratio being zero.
All starting values led to one or the other of these nonsensical values.
Eventually I deduced there must be a metastable value dividing
the two possibilities, but that is hardly reassuring.
I conclude we cannot bootstrap these prior assumptions.
The solutions produced do not tend to the correct variance,
nor is the variance ratio correct,
so they cannot be used to bootstrap the variance.
Philosophically we can be thankful the result failed to converge
so we did not get a false confidence in the solution.
I conclude that linear estimation theory,
while beguiling
and appearing to be a universal guide to practice, is actually incomplete.
The incompleteness will grow in later chapters
with multivariate least squares,
because there the scalar 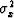 becomes a matrix.
We continue our search for ``universal truth'' by studying more examples.
becomes a matrix.
We continue our search for ``universal truth'' by studying more examples.
Next: NONSTATIONARITY
Up: HOW TO DIVIDE NOISY
Previous: Example of deconvolution with
Stanford Exploration Project
1/13/1998