




![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) we defined linear interpolation
interpolation
as the extraction of values from between mesh points.
In a typical setup (occasionally the role of data and model are swapped),
a model is given on a uniform mesh
and we solve the easy problem of extracting values
between the mesh points with subroutine lint1() .
The genuine problem is the inverse problem, which we attack here.
Data values are sprinkled all around,
and we wish to find a function on a uniform mesh
from which we can extract that data by linear interpolation.
The adjoint operator for subroutine lint1()
simply piles data back into its proper location in model space
without regard to how many data values land in each region.
Thus some model values may have many data points added
to them while other model values get none.
We could interpolate by minimizing the energy in the model gradient,
or that in the second derivative of the model,
or that in the output of any other roughening filter
applied to the model.
we defined linear interpolation
interpolation
as the extraction of values from between mesh points.
In a typical setup (occasionally the role of data and model are swapped),
a model is given on a uniform mesh
and we solve the easy problem of extracting values
between the mesh points with subroutine lint1() .
The genuine problem is the inverse problem, which we attack here.
Data values are sprinkled all around,
and we wish to find a function on a uniform mesh
from which we can extract that data by linear interpolation.
The adjoint operator for subroutine lint1()
simply piles data back into its proper location in model space
without regard to how many data values land in each region.
Thus some model values may have many data points added
to them while other model values get none.
We could interpolate by minimizing the energy in the model gradient,
or that in the second derivative of the model,
or that in the output of any other roughening filter
applied to the model.
Formalizing now our wish
that data ![]() be extractable by linear interpolation
be extractable by linear interpolation ![]() ,from a model
,from a model ![]() ,and our wish that application of a roughening filter
with an operator
,and our wish that application of a roughening filter
with an operator ![]() have minimum energy, we write the fitting goals:
have minimum energy, we write the fitting goals:
| |
(14) |
![\begin{displaymath}
{
\left[
\begin{array}
{rrrrrr}
.8 & .2 & . & . & . & . \...
...
\bold r_m
\end{array} \right]
\quad \approx \ \bold 0
} \end{displaymath}](img70.gif) |
(15) |
The residual vector has two parts,
a data part ![]() on top
and a model part
on top
and a model part ![]() on the bottom.
The data residual
should vanish except where contradictory data values
happen to lie in the same place.
The model residual is the roughened model.
on the bottom.
The data residual
should vanish except where contradictory data values
happen to lie in the same place.
The model residual is the roughened model.
Two fitting goals () are so common in practice
that it is convenient to adopt our least-square fitting
subroutine solver_smp accordingly.
The modification
is shown in module solver_reg .
In addition to specifying the ``data fitting'' operator ![]() (parameter Fop),
we need to pass the ``model regularization'' operator
(parameter Fop),
we need to pass the ``model regularization'' operator ![]() (parameter Aop) and the
size of its output (parameter nAop) for proper memory allocation.
(parameter Aop) and the
size of its output (parameter nAop) for proper memory allocation.
(When I first looked at module solver_reg I was appalled by the many lines of code, especially all the declarations. Then I realized how much much worse was Fortran 77 where I needed to write a new solver for every pair of operators. This one solver module works for all operator pairs and for many optimization descent strategies because these ``objects'' are arguments. These more powerful objects require declarations that are more complicated than the simple objects of Fortran 77. As an author I have a dilemma: To make algorithms compact (and seem simple) requires many careful definitions. When these definitions put in the code, they are careful, but the code becomes annoyingly verbose. Otherwise, the definitions must go in the surrounding natural language where they are not easily made precise.) solver_reggeneric solver with regularization
After all the definitions,
we load the negative of the data into the residual.
If a starting model ![]() is present,
then we update the data part of the residual
is present,
then we update the data part of the residual
![]() and we load
the model part of the residual
and we load
the model part of the residual
![]() .Otherwise we begin from a zero model
.Otherwise we begin from a zero model ![]() and thus
the model part of the residual
and thus
the model part of the residual ![]() is also zero.
After this initialization, subroutine
solver_reg() begins an iteration loop by first computing
the proposed model perturbation
is also zero.
After this initialization, subroutine
solver_reg() begins an iteration loop by first computing
the proposed model perturbation ![]() (called g in the program)
with the adjoint operator:
(called g in the program)
with the adjoint operator:
| (16) |
| (17) |
An example of using the new solver is subroutine invint1.
I chose to implement the model roughening operator ![]() with the convolution subroutine tcai1() ,
which has transient end effects
(and an output length equal to the input length plus the filter length).
The adjoint of subroutine tcai1() suggests perturbations
in the convolution input (not the filter).
invint1invers linear interp.
with the convolution subroutine tcai1() ,
which has transient end effects
(and an output length equal to the input length plus the filter length).
The adjoint of subroutine tcai1() suggests perturbations
in the convolution input (not the filter).
invint1invers linear interp.
Figure shows an example for a (1,-2,1) filter with ![]() .The continuous curve representing the model
.The continuous curve representing the model ![]() passes through the data points.
Because the models are computed with transient convolution end-effects,
the models tend to damp linearly to zero outside the region where
signal samples are given.
passes through the data points.
Because the models are computed with transient convolution end-effects,
the models tend to damp linearly to zero outside the region where
signal samples are given.
|
im1-2+190
Figure 13 Sample points and estimation of a continuous function through them. | 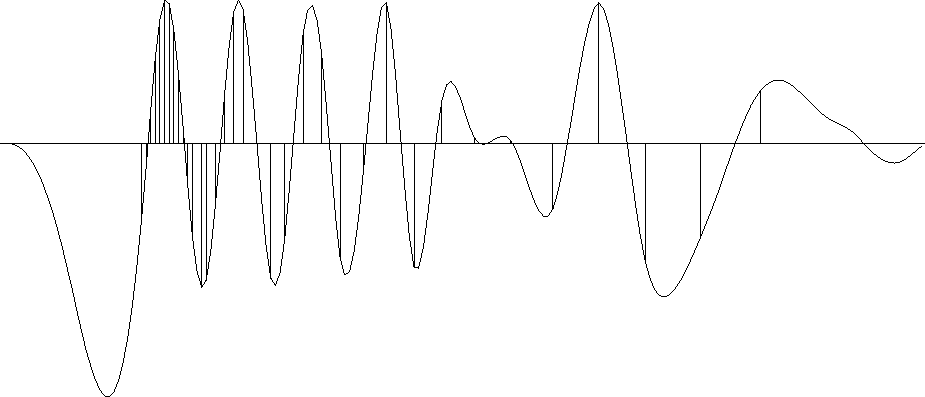 |
![[*]](http://sepwww.stanford.edu/latex2html/movie.gif)





To show an example where the result is clearly a theoretical answer,
I prepared another figure with the simpler filter (1,-1).
When we minimize energy in the first derivative of the waveform,
the residual distributes itself uniformly
between data points
so the solution there is a straight line.
Theoretically it should be a straight line
because a straight line has a vanishing second derivative,
and that condition arises by differentiating by ![]() ,the minimized quadratic form
,the minimized quadratic form
![]() , and getting
, and getting
![]() .(By this logic, the curves between data points in Figure
must be cubics.)
The (1,-1) result is shown in Figure .
.(By this logic, the curves between data points in Figure
must be cubics.)
The (1,-1) result is shown in Figure .
|
im1-1a90
Figure 14 The same data samples and a function through them that minimizes the energy in the first derivative. | 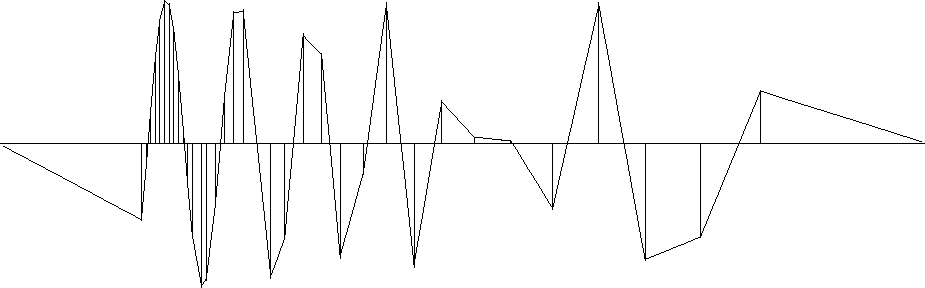 |
The example of
Figure
has been a useful test case for me.
You'll see it again in later chapters.
What I would like to show you here is a movie showing the convergence
to Figure .
Convergence occurs rapidly where data points are close together.
The large gaps, however, fill at a rate of one point per iteration.