




Next: REFERENCES
Up: THE WORLD OF CONJUGATE
Previous: Standard methods
This section includes Sergey Fomel's explanation on the ``magic''
convergence properties of the conjugate-direction methods. It also
presents a classic version of conjugate gradients, which can be found
in numerous books on least-square optimization.
The key idea for constructing an optimal iteration is to update the
solution at each step in the direction, composed by a linear
combination of the current direction and all previous solution steps.
To see why this is a helpful idea, let us consider first the method of
random directions. Substituting expression (47) into
formula (45), we see that the residual power
decreases at each step by
| 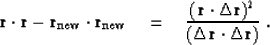 |
(90) |
To achieve a better convergence, we need to maximize the right hand
side of (90). Let us define a new solution step 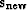 as a combination of the current direction
as a combination of the current direction 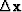 and the previous step
and the previous step  , as follows:
, as follows:
|  |
(91) |
The solution update is then defined as
| 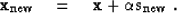 |
(92) |
The formula for  (47) still holds, because we have
preserved in (92) the form of equation (41)
and just replaced with . In fact,
formula (47) can be simplified a little bit. From
(46), we know that
(47) still holds, because we have
preserved in (92) the form of equation (41)
and just replaced with . In fact,
formula (47) can be simplified a little bit. From
(46), we know that  is orthogonal
to
is orthogonal
to 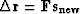 . Likewise,
. Likewise,  should be orthogonal to
should be orthogonal to 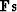 (recall that was
and was at the
previous iteration). We can conclude that
(recall that was
and was at the
previous iteration). We can conclude that
| 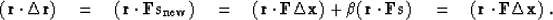 |
(93) |
Comparing (93) with (90), we can see that
adding a portion of the previous step to the current direction does
not change the value of the numerator in expression
(90). However, the value of the denominator can be
changed. Minimizing the denominator maximizes the residual increase at
each step and leads to a faster convergence. This is the denominator
minimization that constrains the value of the adjustable coefficient
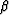 in (91).
in (91).
The procedure for finding is completely analogous to the
derivation of formula (47). We start with expanding the
dot product 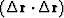 :
:
| 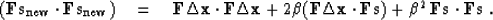 |
(94) |
Differentiating with respect to and setting the derivative to
zero,
we find that
| 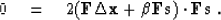 |
(95) |
Equation (95) states that the conjugate direction
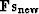 is orthogonal (perpendicular) to the
previous conjugate direction . It also defines the
value of as
is orthogonal (perpendicular) to the
previous conjugate direction . It also defines the
value of as
| 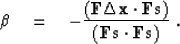 |
(96) |
Can we do even better? The positive quantity that we minimized in
(94) decreased by
| 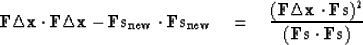 |
(97) |
Can we decrease it further by adding another previous step? In
general, the answer is positive, and it defines the method of
conjugate directions. I will state this result without a formal proof
(which uses the method of mathematical induction).
- If the new step is
composed of the current direction and a combination of all the
previous steps:
| 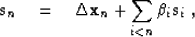 |
(98) |
then the optimal convergence is achieved when
| 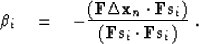 |
(99) |
- The new conjugate direction is orthogonal to the previous ones:
| 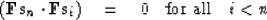 |
(100) |
To see why this is an optimally convergent method, it is sufficient to
notice that vectors 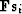 form an orthogonal basis in
the data space. The vector from the current residual to the smallest
residual also belongs to that space. If the data size is n, then n
basis components (at most) are required to represent this vector, hence
no more then n conjugate-direction steps are required to find the
solution.
form an orthogonal basis in
the data space. The vector from the current residual to the smallest
residual also belongs to that space. If the data size is n, then n
basis components (at most) are required to represent this vector, hence
no more then n conjugate-direction steps are required to find the
solution.
The computation template for the method of conjugate directions is
 iterate {
iterate {
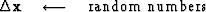

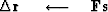
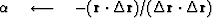

 }
}
What happens if we ``feed'' the method with gradient directions
instead of just random directions? It turns out that in this case we
need to remember from all the previous steps 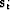 only the one
that immediately precedes the current iteration. Let us derive a
formal proof of that fact as well as some other useful formulas
related to the method of conjugate gradients .
only the one
that immediately precedes the current iteration. Let us derive a
formal proof of that fact as well as some other useful formulas
related to the method of conjugate gradients .
According to formula (46), the new residual is orthogonal to the conjugate direction . According to the orthogonality condition
(100), it is also orthogonal to all the previous
conjugate directions. Defining equal to the gradient
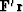 and applying the definition of the adjoint
operator, it is convenient to rewrite the orthogonality condition in
the form
and applying the definition of the adjoint
operator, it is convenient to rewrite the orthogonality condition in
the form
| 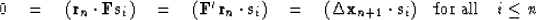 |
(101) |
According to formula (98), each solution step is just a linear combination of the gradient 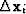 and
the previous solution steps. We deduce from formula
(101) that
and
the previous solution steps. We deduce from formula
(101) that
| 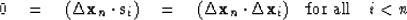 |
(102) |
In other words, in the method of conjugate gradients, the current
gradient direction is always orthogonal to all the previous
directions. The iteration process constructs not only an orthogonal
basis in the data space but also an orthogonal basis in the model
space, composed of the gradient directions.
Now let us take a closer look at formula (99). Note
that is simply related to the residual step at
i-th iteration:
| 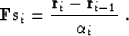 |
(103) |
Substituting relationship (103) into formula
(99) and applying again the definition of the adjoint
operator, we obtain
| 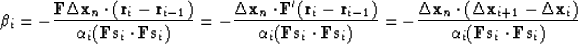 |
(104) |
Since the gradients are orthogonal to each other,
the dot product in the numerator is equal to zero unless i = n-1. It
means that only the immediately preceding step 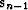 contributes to the definition of the new solution direction
contributes to the definition of the new solution direction 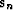 in (98). This is precisely the property of the
conjugate gradient method we wanted to prove.
in (98). This is precisely the property of the
conjugate gradient method we wanted to prove.
To simplify formula (104), rewrite formula (47) as
| 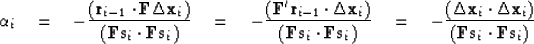 |
(105) |
Substituting (105) into (104), we obtain
| 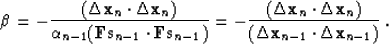 |
(106) |
The computation template for the method of conjugate gradients is then
 iterate {
iterate {
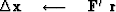 if not the first iteration
if not the first iteration 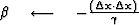
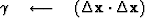

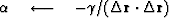 }
}
Module conjgrad ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) provides an
implementation of this method. The interface is exactly similar to
that of cgstep , therefore you can
use conjgrad as an argument to solver
.
provides an
implementation of this method. The interface is exactly similar to
that of cgstep , therefore you can
use conjgrad as an argument to solver
.
When the orthogonality of the gradients, (implied by the classical
conjugate-gradient method) is not numerically assured, the
conjgrad algorithm may loose its convergence properties. This
problem does not exist in the algebraic derivations, but appears in
practice because of numerical errors. A proper remedy is to
orthogonalize each new gradient against previous ones. Naturally, this
increases the cost and memory requirements of the method.
module conjgrad_mod {
real, dimension (:), allocatable, private :: s, ss
contains
subroutine conjgrad_close () {
if( allocated( s)) deallocate( s, ss)
}
function conjgrad( forget, x, g, rr, gg) result( stat) {
integer :: stat
real, dimension (:) :: x, g, rr, gg
logical :: forget
real, save :: rnp
double precision :: rn, alpha, beta
rn = sum( dprod( g, g))
if( .not. allocated( s)) { forget = .true.
allocate( s (size (x ))); s = 0.
allocate( ss (size (rr))); ss = 0.
}
if( forget .or. rnp < epsilon (rnp))
alpha = 0.d0
else
alpha = - rn / rnp
s = g + alpha * s
ss = gg + alpha * ss
beta = sum( dprod( ss, ss))
if( beta > epsilon( beta)) {
alpha = rn / beta
x = x + alpha * s
rr = rr + alpha * ss
}
rnp = rn; forget = .false.; stat = 0
}
}
Next: REFERENCES
Up: THE WORLD OF CONJUGATE
Previous: Standard methods
Stanford Exploration Project
2/27/1998