




Now let us examine the theory and coding behind the above examples.
Define a roughening filter ![]() and a data signal
and a data signal ![]() at some stage of interpolation.
The fitting goal is
at some stage of interpolation.
The fitting goal is
![]() where the filter
where the filter ![]() has
at least one time-domain coefficient constrained to be nonzero
and the data contains both known and missing values.
Think of perturbations
has
at least one time-domain coefficient constrained to be nonzero
and the data contains both known and missing values.
Think of perturbations ![]() and
and ![]() .We neglect the nonlinear term
.We neglect the nonlinear term ![]() as follows:
as follows:
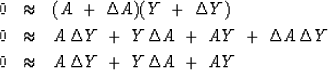 |
(31) | |
| (32) | ||
| (33) |
Linearizing a nonlinear fitting goal such as
(33) seems reasonable.
I linearized this way to first obtain the results of this chapter.
Never-the-less, I find linearizing is a dangerous procedure
that quickly leads to many problems.
In reality, the term ![]() might not actually be small and the solution might not converge.
You don't know how small is small,
because these are not scalars but operators.
The answer will depend on where you start from.
Strange things happen. You can feel a sense of frustration.
There is good news:
Two stage linear least squares offers relief.
You should first use linear least squares to get close to your answer.
Generally,
when finding the filter A we have plenty of regression equations,
so we can afford to neglect the ones that depend upon unknown data.
Then you can fix the filter and in a second stage, find the missing data.
If you don't have enough regression equations
because your data is irregularly distributed,
then you can use binning.
Still not enough? Try coarser bins.
The point is that nonlinear solvers will not work unless you
first get sufficiently close to the solution,
and the way you get close is by arranging first to
solve a sensible (though approximate) linearized problem.
Only as a last resort, after you have gotten as near as you can,
should you use the nonlinear least-squares techniques described below.
might not actually be small and the solution might not converge.
You don't know how small is small,
because these are not scalars but operators.
The answer will depend on where you start from.
Strange things happen. You can feel a sense of frustration.
There is good news:
Two stage linear least squares offers relief.
You should first use linear least squares to get close to your answer.
Generally,
when finding the filter A we have plenty of regression equations,
so we can afford to neglect the ones that depend upon unknown data.
Then you can fix the filter and in a second stage, find the missing data.
If you don't have enough regression equations
because your data is irregularly distributed,
then you can use binning.
Still not enough? Try coarser bins.
The point is that nonlinear solvers will not work unless you
first get sufficiently close to the solution,
and the way you get close is by arranging first to
solve a sensible (though approximate) linearized problem.
Only as a last resort, after you have gotten as near as you can,
should you use the nonlinear least-squares techniques described below.
Let us use matrix algebraic notation to rewrite the fitting goals (33). For this we need mask matrices
(diagonal matrices with ones on the diagonal
where variables are free and zeros where they are constrained
i.e., where ![]() and
and ![]() ).
The free-mask matrix for missing data is denoted
).
The free-mask matrix for missing data is denoted ![]() and that for the PE filter is
and that for the PE filter is ![]() .The fitting goal (33) becomes
.The fitting goal (33) becomes
| |
(34) |
| (35) |
For a 3-term filter and a 7-point data signal, the fitting goal (34) becomes
![\begin{displaymath}
\left[
\begin{array}
{rrrrrrrrrr}
a_0& . & . & . & . & . &...
...r_7 \\ r_8 \\ 0
\end{array} \right]
\quad \approx \ \bold 0\end{displaymath}](img103.gif) |
(36) |
| |
(37) |
| (38) |
| (39) |
| |
(40) | |
| (41) |
This is the same idea as all the linear fitting goals we have been solving,
except that now we recompute
the residual ![]() inside the iteration loop
so that as convergence is achieved (if it is achieved),
the neglected nonlinear term
inside the iteration loop
so that as convergence is achieved (if it is achieved),
the neglected nonlinear term ![]() tends to zero.
tends to zero.
I no longer exhibit the nonlinear solver missif until I find an example where it produces noticibly better results than multistage linear-least squares.